BowerAccess
note
large language models (LLMs) 在当今时代快速发展,成为新一代科技发展创新浪潮的热点。
LLMs 通常具有数以亿计甚至数以百亿计的参数,这使得它们能够捕获语言中的复杂模式和语义关系,但也引入了极高的内存资源开销。以 GPT-3 举例,它的参数量为 175B,在未经优化的条件下,它的运行时内存开销大于 700GB 。这远远超出了许多边缘设备的 GPU 显存大小(如树莓派 4b 的 GPU 显存大小为 2GB)。
PowerInfer 是发表在 SOSP'24 上的工作,它可以使得 175B 的 LLM 部署在单个商用级 GPU 上,这得益于它观察到了 LLM 访存的稀疏性。即在 LLM 中,并不是所有的神经元都对于计算结果有影响,只有少部分神经元会影响最终的结果,通过只将重要的神经元加载到 GPU 显存中,并选择性地对神经元进行计算,来减少 LLM 的运行时内存开销。
warning
这是一个我们制作的新Lab, 欢迎大家测试并提出意见。
在 BowerAccess Lab 中,我们希望你参考 PowerInfer 的思想修改 chcore,进而在其上部署并优化一个与 LLM 类似的应用程序 llm(你可以在shell中通过./test_llm进行访问)。具体而言:
llm 是一个 CPU 内存开销极大的程序,它会使用 mmap() 映射一个 1MB 大小的特殊内存空间(用 MAP_LLM 进行标识)并访问其中的数据完成功能,这远远超过了 chcore 管理的 MAP_LLM 物理内存大小(出于题目设计考虑,我们将这种特殊内存空间的大小限制为 1MB),直接运行会产生大量的 Page Fault,引入了极大的运行时开销。
幸运的是,llm 的访存具有和 LLM 类似的稀疏性:
-
它虽然映射了非常大的内存空间,但是只会访问其中的一个特定的内存页面子集
-
只会按照单调递增的顺序访问内存页面
llm 的 mmap() 会传递一个特殊的特殊的 MAP_LLM 参数。
llm 的访存模式与下图相似(但访问的页面并不相同):
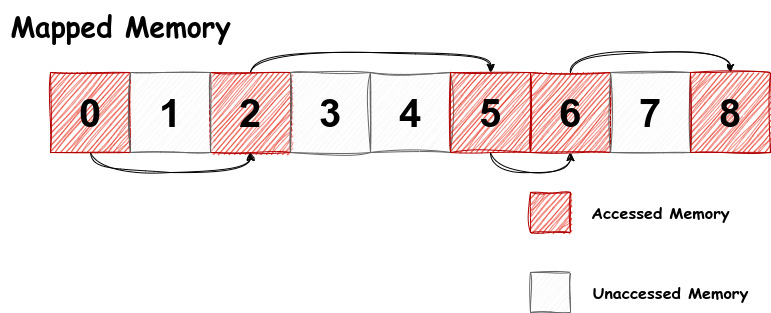
虽然程序总共映射了 9 个页面,但是只访问了 0, 2, 5, 6, 8 这几个页面,且一定按照 0 -> 2 -> 5 -> 6 -> 8 的顺序访问,并没有访问 1, 3, 4, 7 这几个页面。
它的代码是(再次强调它只是示例代码,和真实的 llm 代码相似但不同):
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <unistd.h>
#define PAGE_SIZE 4096
int main() {
const char *filename = "weight.dat";
int fd = open(filename, O_RDWR | O_CREAT, 0666);
if (fd < 0) {
perror("open");
return EXIT_FAILURE;
}
// alloc 9 pages
if (ftruncate(fd, 9 * PAGE_SIZE) == -1) {
perror("ftruncate");
close(fd);
return EXIT_FAILURE;
}
// map the file, use the special `MAP_LLM` flag
char *map = mmap(NULL, 9 * PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_LLM, fd, 0);
if (map == MAP_FAILED) {
perror("mmap");
close(fd);
return EXIT_FAILURE;
}
// access page 0, 2, 5, 6, 8
int pages_to_access[] = {0, 2, 5, 6, 8};
for (size_t i = 0; i < sizeof(pages_to_access) / sizeof(pages_to_access[0]); i++) {
int page_number = pages_to_access[i];
map[page_number * PAGE_SIZE] = 'A' + page_number;
printf("Accessed page %d, first byte: %c\n", page_number, map[page_number * PAGE_SIZE]);
}
if (munmap(map, 9 * PAGE_SIZE) == -1) {
perror("munmap");
}
close(fd);
return EXIT_SUCCESS;
}
根据 llm 所具有的稀疏的、可预测的访存模式,我们可以设计在 page fault 发生时,预取(prefetch)即将访存的多个页面,这样就可以减少 page fault 的次数,提高了运行性能。
warning
我们只提供 llm 的二进制文件,并不提供源码文件。请自由发挥,判断出 llm 的具体访存模式。
思考题 8
阅读 kernel/object/user_fault.c 下的 sys_user_fault_map_batched 函数,并回答如下问题
- “
MAP_LLM地址空间具有容量限制”这个特点在代码中是如何实现的? - 对比它和
sys_user_fault_map函数的区别,并回答我们为什么需要引入一个新的系统调用?
练习题 9
为了实现在 page fault 的时候预取页面的功能,我们需要修改 user/system-services/system-servers/fs_base/fs_page_fault.c 文件:
- 实现
predict_prefetch_pages函数。 - 实现
handle_one_fault函数中针对MAP_LLM的预取(prefetch)功能,实现需要predict_prefetch_pages和usys_user_fault_map_batched函数的配合。 user_fault中为处理用户地址缺页的Handler。
success
以上为Lab5的所有内容